
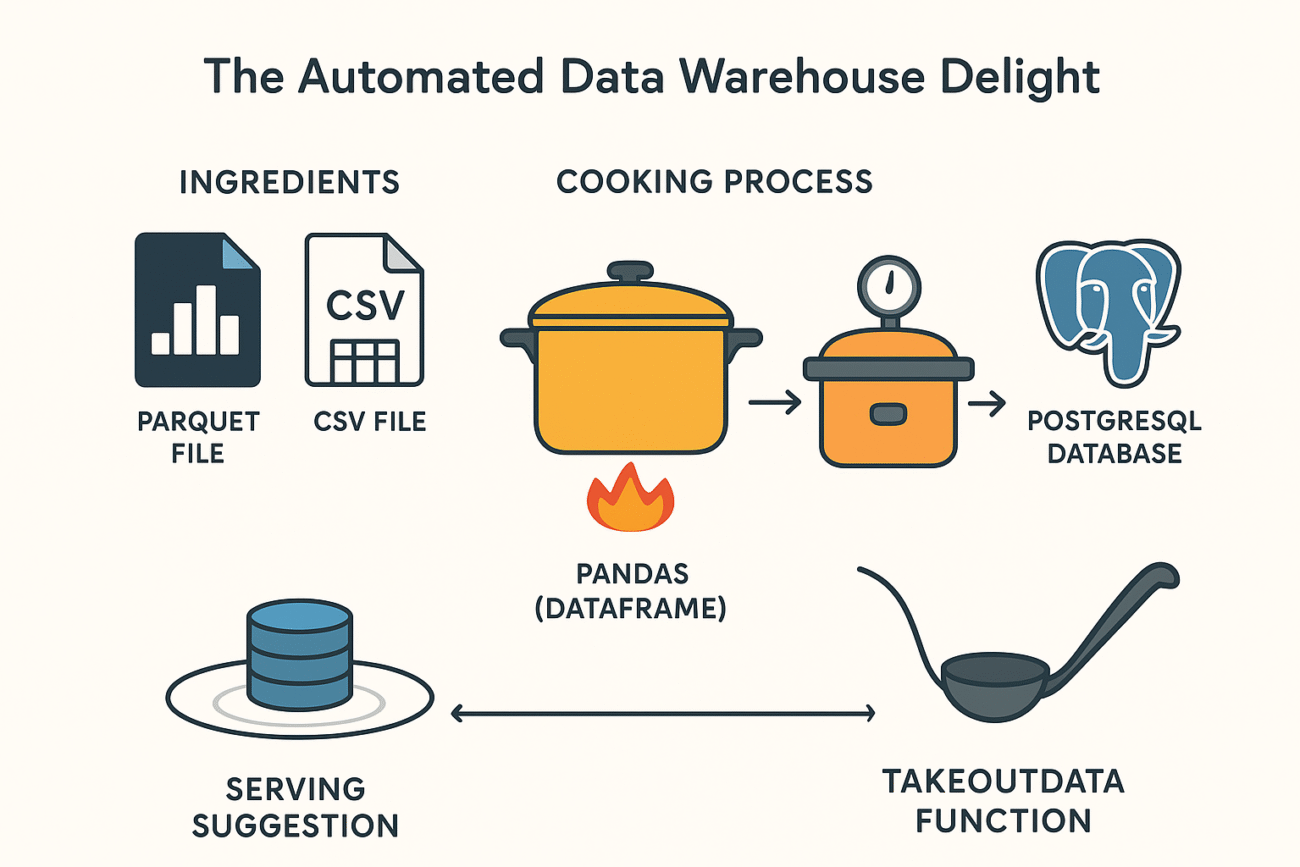
Main Dish (Idea): The Automated Data Warehouse Delight
This project aims to create a local, readily accessible data store within a PostgreSQL database, populating it with data from various sources (Parquet files, CSV files) and also, creates a way to quickly extract the data and preview it. The goal is to create a simplified database to store model outputs/forecasts in a way that they can be accessed for other applications.
Ingredients (Concepts & Components):
- Parquet File: The main course. A compressed, column-oriented data file containing valuable forecasting data.
- CSV File: A savory side dish. A comma-separated value file containing relational data between locations/grid IDs and countries.
- Pandas (DataFrame): The mixing bowl. Used for data manipulation, cleaning, and preparation before it goes into the database.
- SQLAlchemy: The high-pressure cooker. Enables the project to connect to, and interact with, the PostgreSQL database.
- PostgreSQL Database: The refrigerator. The final destination, the data warehouse to store and serve the prepared data.
to_sqlfunction: The conveyor belt. Moves the data from the Pandas DataFrame to the database table.- Config file: The secret spice. The configuration file holds the database password/credentials.
takeoutdataFunction: The serving ladle. Allows users to selectively retrieve data using SQL queries.
Cooking Process (How It Works):
- Gather the Ingredients: The chef starts by sourcing all the needed ingredients, the Parquet and CSV files from their location.
- Prepping the Parquet: The main Parquet ingredient is read into a Pandas DataFrame, which is then indexed (if required). The chef inspects the data, ensuring it’s ready for the next step.
- Seasoning the CSV: The same process is applied to the CSV file: read into a DataFrame, manipulated, cleaned and made ready for storage.
- Connecting the Kitchen: SQLAlchemy is used to create a connection to the PostgreSQL database, authenticating with the password stored in the ‘config’ file.
- High-Pressure Insertion: The
to_sqlfunction from Pandas is used to force the data from the DataFrames into the PostgreSQL tables. Theif_exists='replace'argument ensures that if the table already exists, it gets overwritten for the freshest data! - Preparing the Ladle: A generic function,
takeoutdata, is created. This function takes any SQL query, executes it against the database, and returns the results in a Pandas DataFrame, ready for review and analysis. - Taste Testing: The chef uses the
takeoutdatafunction with simple “SELECT *” queries to make sure the data has been properly stored and can be retrieved.
Serving Suggestion (Outcome):
The final dish is a fully populated PostgreSQL database. Model outputs and auxiliary data are neatly organized in tables, accessible via SQL queries. The function allows for quickly retrieving specific cuts of data, which can be readily used in other data science projects, visualizations, or applications.